ElasticSearch
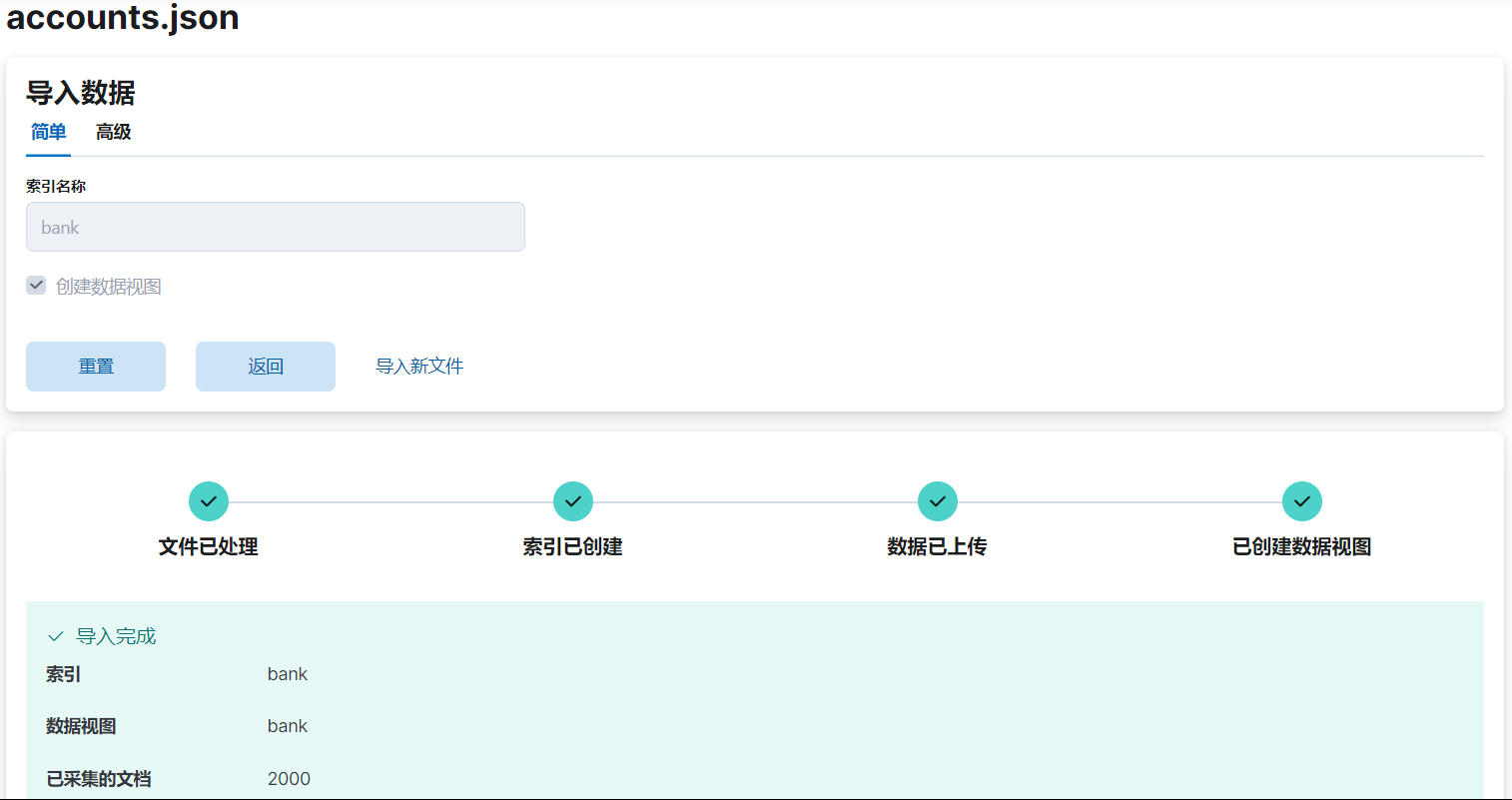
了解或者熟悉全文搜索引擎的朋友都应该知道:ElasticSearch、Lucene、Solr、Sphinx等著名的搜索引擎。今天探讨其中使用比较广的ElasticSearch。以下需提前安装好ES和Kibana,通过Kibana导入官方测试数据accounts.json到bank索引作为测试数据
一、基操勿六
ES 中数据的操作方式是 restful 风格的,可以通过 GET、PUT、POST、DELETE 的方式来实现数据的增删改查。
1. ES 字段类型
- keyword - 常用于存储结构化内容,比如email地址,电话号码,名称等等文本。作为一个整体存储的,不会对其进行分词处理
- text - 文本类型,常用于保存大段文本,会对字符串进行分词处理
- integer - 整数
- long - 浮点型数据
- date - 日期格式,比如 '2019-12-01 12:00:00'
- boolean - 布尔型,true/false
- 数组 - 可以直接将某个字段作为数组使用,但是添加的元素必须是相同的
2. 基础查询
以下数据均来自bank索引导入的官方测试数据accounts.json
# 查看所有索引
GET /_cat/indices
# 查看 bank 中的全部数据,不指定 size 参数的话默认最多只返回 10 条数据
GET /bank/_search
# 根据 balance 倒序排序,sort 后接一个数组,表示可以根据多个字段进行正序,逆序的排序
GET /bank/_search
{
"sort": [
{"balance": {"order": "desc"}}
]
}
# from 表示从第 n 个开始获取数据,从 0 开始取值,size 表示获取数据量的大小。
# 比如说从第0条数据开始,获取5条数据
GET /bank/_search
{
"sort": [
{"balance": {"order": "asc"}}
],
"from": 0,
"size": 5
}
# 多条件查询,类似于 sql 中的 and、or、not,对应在 es 中就是 must,should,must_not
GET /bank/_search
{
"query": {
"bool": {
"should": [
{"match": {"age": 24}},
{"match": {"age": 25}}
],
"must_not": [
{"match": {"gender": "M"}}
]
}
}
}
# 数字过滤也在 bool 这个 key 下一级,用到 filter 和 range 关键字
# 大小于的关键字和 Django 里的是一样的 gt, gte, lt, lte
GET /bank/_search
{
"query": {
"bool":{
"filter": {
"range": {
"age": {
"gte": 21,
"lte": 22
}
}
}
}
}
}
# 只是直接搜索大小于的操作可以简化
GET /bank/_search
{
"query": {
"range": {
"age": {
"gte": 21,
"lte": 22
}
}
}
}
# term: 精确查找,对于搜索的内容也是直接整体查找
GET /bank/_search
{
"query": {
"term": {
"address": {
"value": "837 Horace Court"
}
}
}
}
# terms: 同时搜索多个精确字段值
GET /bank/_search
{
"query": {
"terms": {
"address": ["166 Irvington Place", "446 Halleck Street"]
}
}
}
# match 表示模糊搜索,会将搜索的内容先进行分词操作,然后搜索
# 搜索 bank 这个 index 中 address 字段中包含 "cove" 或者 包含 "lane" 的的数据
# 但是 keyword 类型的字段数据不会分词,所以也需要完全匹配才能查询得到
GET /bank/_search
{
"query": {
"match": {"address": "Cove Lane"}
}
}
# 匹配短语,不加其他参数会匹配包含这个短语、且顺序一致的数据。实现 cove lane 作为一个整体进行查询
GET /bank/_search
{
"query": {
"match_phrase": {"address": "Cove Lane"}
}
}
# match_phrase_prefix 匹配前缀,注意只能用来查询text类型,不能用于keyword
GET /bank/_search
{
"query": {
"match_phrase_prefix": {
"address": "837 Horace Co"
}
}
}
# multi_match 针对于多个字段进行 match 操作,fields 是一个数组,里面是需要搜索的字段,需要都能匹配上搜索的关键字
GET /bank/_search
{
"query": {
"multi_match": {
"query": "Horace",
"fields": ["name", "address"]
}
}
}
# 两个通配符,一个是 *,一个是 ?
# * 的作用是 0 到 n 个字符长度
GET /bank/_search
{
"query": {
"wildcard": {
"address": {
"value": "166 Irvington P*"
}
}
}
}
# ? 的作用是匹配任意单个字符
GET /bank/_search
{
"query": {
"wildcard": {
"address": {
"value": "166 Irvington ?lace"
}
}
}
}
二、聚合查询
在 ES 中的聚合是支持套娃(嵌套)操作的,可以分为大概四种聚合:
- bucketing(桶聚合) - 类似于分类分组,按照某个 key 将符合条件的数据都放到该类别的组中
- mertic(指标聚合) - 计算一组文档的相关值,比如最大,最小值
- matrix(矩阵聚合) - 根据多个 key 从文档中提取值生成矩阵
- pipeline(管道聚合) - 将其他聚合的结果再次聚合输出
1. 指标聚合
# 最外层的 aggs 表示是聚合操作,avg_balance 是聚合的名称,avg 则表示是平均值聚合
# 里面的 field 表示聚合的字段是 balance 字段
# 不添加 size=0,除了会返回我们的聚合结果,还会返回聚合的源数据
GET /bank/_search
{
"size": 0,
"aggs": {
"avg_balance": {
"avg": {
"field": "balance"
}
}
}
}
# 对某个字段进行去重后统计总数,注意这个统计对于 text 字段属性是不生效的
GET /bank/_search
{
"size": 0,
"aggs": {
"age_count": {
"cardinality": {
"field": "age"
}
}
}
}
# 聚合统计汇总,如总数,最大值,最小值,平均值等
GET /bank/_search
{
"size": 0,
"aggs": {
"age_stats": {
"stats": {
"field": "age"
}
}
}
}
# extended_stats 还能获得方差,标准差等数据
GET /bank/_search
{
"size": 0,
"aggs": {
"age_stats": {
"extended_stats": {
"field": "age"
}
}
}
}
# 最大值最小值的关键字是 max 和 min
GET /bank/_search
{
"size": 0,
"aggs": {
"max_age": {
"max": {"field": "age"}
},
"min_age": {
"min": {"field": "age"}
}
}
}
# 百分位的统计,用到的关键字是 percentiles,会输出 [1, 5, 25, 75, 95, 99] 的统计数
GET /bank/_search
{
"size": 0,
"aggs": {
"age_percentiles": {
"percentiles": {
"field": "age"
}
}
}
}
# 可以指定统计的百分位列表,比如我们只想知道 [60, 70, 80, 90] 的数据
GET /bank/_search
{
"size": 0,
"aggs": {
"age_percentiles": {
"percentiles": {
"field": "age",
"percents": [60, 70, 80, 90]
}
}
}
}
# 和前面的百分位统计相反,前面是根据百分位获取该百分位的数据,这个则是根据数据获取在系统中的百分位
GET /bank/_search
{
"size": 0,
"aggs": {
"age_ranks": {
"percentile_ranks": {
"field": "age",
"values": [20, 25, 28, 32, 36]
}
}
}
}
# 字符串统计聚合 string_stats
GET /bank/_search
{
"size": 0,
"aggs": {
"last_name_stats": {
"string_stats": {"field": "lastname"}
}
}
}
# sum 统计总和
GET /bank/_search
{
"size": 0,
"aggs": {
"age_sum": {
"sum": {"field": "age"}
}
}
}
# 每一个聚合操作里,都可以进行 query 的条件筛选
GET /bank/_search
{
"size": 0,
"query": {"match": {"age": "21"}},
"aggs": {
"balance_sum": {
"sum": {"field": "balance"}
}
}
}
# count 统计总数
GET /bank/_search
{
"size": 0,
"aggs": {
"age_count": {
"value_count": {
"field": "age"
}
}
}
}
# top hit 根据条件返回符合条件的前几条数据,通过 size 控制返回的数量
# top_hits 的操作是在第一个 aggs 聚合操作条件下,进行再次聚合
# 获取各个 age 的数据中,按照 balance 字段进行倒序排序的前三
GET /bank/_search
{
"size": 0,
"aggs": {
"top_ages": {
"terms": {
"field": "age",
"size": 30
},
"aggs": {
"top_balance_hits": {
"top_hits": {
"size": 3,
"sort": [{"balance": {"order": "desc"}}]
}
}
}
}
}
}
2. 桶聚合
桶(bucket)聚合并不像指标(metric)聚合一样在字段上计算,而是会创建数据的桶,可以理解为分组,根据某个字段进行分组,将符合条件的数据分到同一个组里。桶聚合可以有子聚合,意思就是在分组之后,可以在每个组里再次进行聚合操作,子聚合的数据就是每个组的数据
# 根据 age 字段对数据进行分组,结果 buckets 是数组,key 为 age 的值,doc_count 为该 age 值的数据条数
GET /bank/_search
{
"size": 0,
"aggs": {
"bucket_age": {
"terms": {
"field": "age",
"size": 20
}
}
}
}
# 过滤聚合,筛选出 gender 的值为 "F" 的数据,然后对其 balance 取平均数
GET /bank/_search
{
"size": 0,
"aggs": {
"bucket_gender": {
"filter": {"term": {"gender": "F"}},
"aggs": {
"avg_balance": {"avg": {"field": "balance"}}
}
}
}
}
# 多桶过滤聚合 filters
GET /bank/_search
{
"size": 0,
"aggs": {
"bucket_gender": {
"filters": {
"filters": {
"female": {"term": {"gender": "F"}},
"male": {"term": {"gender": "M"}}
}
},
"aggs": {
"avg_balance": {"avg": {"field": "balance"}}
}
}
}
}
# 全局聚合 global,聚合性别为M和全部数据两个的平均数据来比对
GET /bank/_search
{
"size": 0,
"query": {"match": {"gender": "M"}},
"aggs": {
"total_balance_avg": {
"global": {},
"aggs": {
"avg_balance": {
"avg": {"field": "balance"}
}
}
},
"female_balance_avg": {
"avg": {
"field": "balance"
}
}
}
}
# 直方图聚合 histogram。field 为要进行直方图聚合的字段,这里是 age 字段,interval 字段为进行划分的区间
GET /bank/_search
{
"size": 0,
"aggs": {
"age_histogram": {
"histogram": {
"field": "age",
"interval": 5
}
}
}
}
# 指定起止范围,使用extended_bounds.min 和 extended_bounds.max 来限定返回数据的最大最小值
GET /bank/_search
{
"size": 0,
"aggs": {
"age_histogram": {
"histogram": {
"field": "age",
"interval": 5,
"extended_bounds": {
"min": 15,
"max": 60
}
}
}
}
}
# 范围聚合 range。指定范围来返回各个桶的数据,这个和直方图聚合类似,不过这个操作更灵活,步长不会固定死
# from 是闭区间的,to 是开区间的,如果区间两边没有限制,不填写相应的 from 和 to 参数即可
GET /bank/_search
{
"size": 0,
"aggs": {
"age_range": {
"range": {
"field": "age",
"keyed": true,
"ranges": [
{"to": 25},
{"from": 25, "to": 35},
{"from": 35}
]
}
}
}
}
# 在上面的桶聚合操作之后,还可以对每个桶进行子指标聚合,比如最大最小值,平均值,或者统计值等
GET /bank/_search
{
"size": 0,
"aggs": {
"age_range": {
"range": {
"field": "age",
"ranges": [
{"to": 25},
{"from": 25, "to": 35},
{"from": 35}
]
},
"aggs": {
"age_stats": {
"stats": {
"field": "age"
}
}
}
}
}
}
# 稀有词聚合 rare terms aggregation
# 比如根据 age 进行聚合,统计在文档中出现的次数,想获取出现次数最少的几个,或者指定出现次数少于 50 的 age 值
# max_doc_count 指定的出现次数最大的值,还可使用范围过滤,include/exclude
GET /bank/_search
{
"size": 0,
"aggs": {
"rare_age": {
"rare_terms": {
"field": "age",
"max_doc_count": 50,
"exclude": [29, 27, 24]
}
}
}
}
3. 矩阵聚合
在指标聚合的介绍中,有一个聚合统计汇总参数是 stats,会返回对应字段的最大值、最小值、总数等数据,矩阵聚合 matrix 可以理解成是多个字段的 stats 的集合,结果字段说明如下
-
count: 总数
-
mean: 平均值
-
variance: 方差
-
skewness: 偏度
-
kurtosis: 峰度
-
covariance: 协方差
-
correlation: 与其他字段的相关性,比如 age 到 age 字段的相关性就是 1.0
GET /bank/_search
{
"size": 0,
"aggs": {
"field_statis": {
"matrix_stats": {
"fields": ["age", "balance"]
}
}
}
}