深度学习之OpenCV图像处理
1 色彩空间及其互相转换
1.1 色彩空间
1.1.1 RGB
RGB色彩空间是一种基于红、绿、蓝三原色的加色色彩空间。它是用于显示器和电视机的颜色空间,也是用于大多数数字图像的色彩空间。RGB 色彩空间使用三个分量来表示颜色:红色、绿色和蓝色。每个分量都是一个介于 0 到 255 之间的数字,其中 0 表示该原色不存在,255 表示该原色完全存在。
1.1.2 HSV
HSV 色彩空间是一种使用色相、饱和度和值来表示颜色的色彩空间。它是一种直观的色彩空间,与人眼感知颜色的方式更加接近。HSV 色彩空间的三个分量:
- 色相(Hue):指的是颜色的基本属性,例如红色、黄色、绿色等。色相通常用角度来表示,范围为0-360度。
- 饱和度(Saturation):指的是颜色的纯度,也就是颜色中灰色成分的多少。饱和度越高,颜色越纯净;饱和度越低,颜色越灰暗。饱和度通常用百分比来表示,范围为0-100%。
- 值(Value):指的是颜色的亮度,也就是颜色的明暗程度。值越高,颜色越明亮;值越低,颜色越暗淡。值通常用百分比来表示,范围为0-100%。
1.1.3 HLS
HLS 色彩空间是一种使用色相、饱和度和明度来表示颜色的色彩空间。HLS 色彩空间的三个分量:
- 色相(Hue): 色相是指颜色的基本属性,通常用角度来表示,范围为0°到360°。0°代表红色,120°代表绿色,240°代表蓝色,360°又回到红色。
- 饱和度(Saturation): 饱和度是指颜色的纯度,取值范围为0%到100%。0%表示灰色,100%表示完全饱和。
- 明度(Lightness): 明度是指颜色的亮度,取值范围为0%到100%。0%表示黑色,100%表示白色。
1.1.4 YUV
YUV 色彩空间是一种使用亮度(Y)和两个色度分量(U和V)来表示颜色的颜色空间。它主要用于电视和视频领域。YUV 色彩空间的三个分量:
- Y:代表亮度,也就是灰度值。
- U:代表蓝色和黄色之间的色度分量。
- V:代表红色和青色之间的色度分量。
1.1.5 CMY & CMYK
CMY 色彩空间是一种基于减色原理的颜色空间,使用青色 (Cyan)、品红 (Magenta) 和黄色 (Yellow) 三原色来表示颜色。它通常用于印刷和出版领域,因为CMY油墨可以很好地吸收光线,从而产生各种各样的颜色。CMYK 是 CMY 的扩展增加了黑色分量。这是因为 CMY 无法完美地再现黑色,因此添加黑色分量可以提高阴影和暗调的准确性。
1.1.6 Lab
Lab 色彩空间是一种基于人眼感知的色彩空间,比其他颜色空间(如 RGB 和 CMYK)更接近于感知颜色。
Lab 色彩空间的三个分量:
- L:代表亮度,取值范围为 0-100,0 表示黑色,100 表示白色。
- a:代表从红色到绿色的范围,取值范围为 -128 到 127,-128 表示绿色,127 表示红色。
- b:代表从蓝色到黄色的范围,取值范围为 -128 到 127,-128 表示蓝色,127 表示黄色。
色彩空间转换示例代码
def convert_color():
rgb_img = cv.imread('./mini_img/test/girl-256.jpg')
color_spaces = ['RGB', 'GRAY', 'HSV', 'HLS', 'YUV', 'Lab']
images = [rgb_img]
for i, name in enumerate(color_spaces):
if not i:
continue
img = cv.cvtColor(rgb_img, getattr(cv, f'COLOR_BGR2{name}'))
images.append(img)
for name, img in zip(color_spaces, images):
cv.imshow(name, img)
cv.waitKey()
cv.destroyAllWindows()

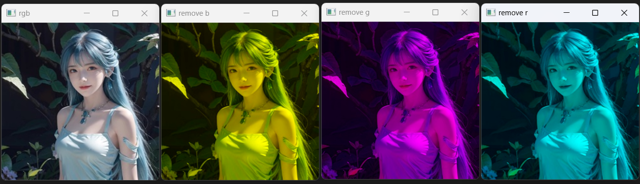
移除色彩通道示例
def colour_channel():
rgb_img = cv.imread('./mini_img/test/girl-256.jpg')
print(rgb_img.shape)
for i in range(-1, 3):
if i == -1:
name = 'rgb'
img = rgb_img
else:
name = f'remove {"bgr"[i]}'
img = copy.deepcopy(rgb_img)
img[:, :, i] = 0
cv.imshow(name, img)
cv.waitKey()
cv.destroyAllWindows()
灰度图像二值化示例
def binary_img():
img = cv.imread('./mini_img/test/gray-512.jpg')
cv.imshow('gray', img)
t, bi = cv.threshold(img, 120, 255, cv.THRESH_BINARY)
cv.imshow('binary', bi)
t, bi_inv = cv.threshold(img, 100, 255, cv.THRESH_BINARY_INV)
cv.imshow('binary_inv', bi_inv)
cv.waitKey()
cv.destroyAllWindows()

2 形态变换
2.1 缩放
def size():
img = cv.imread('./mini_img/test/girl-512.jpg')
cv.imshow('1.0', img)
rows, cols, _ = img.shape
bigger = cv.resize(img, (int(1.25 * cols), int(1.25 * rows)))
cv.imshow('bigger', bigger)
for ratio in [0.8, 0.6, 0.4, 0.2]:
smaller = cv.resize(img, None, fx=ratio, fy=ratio, interpolation=cv.INTER_CUBIC)
cv.imshow(str(ratio), smaller)
cv.waitKey()
cv.destroyAllWindows()
2.2 翻转
def flip():
image = cv.imread('./mini_img/test/girl-256.jpg')
vertical_flip = cv.flip(image, 0)
horizontal_flip = cv.flip(image, 1)
both_axes_flip = cv.flip(image, -1)
cv.imshow('Original', image)
cv.imshow('Vertical Flip', vertical_flip)
cv.imshow('Horizontal Flip', horizontal_flip)
cv.imshow('Both Axes Flip', both_axes_flip)
cv.waitKey(0)
cv.destroyAllWindows()
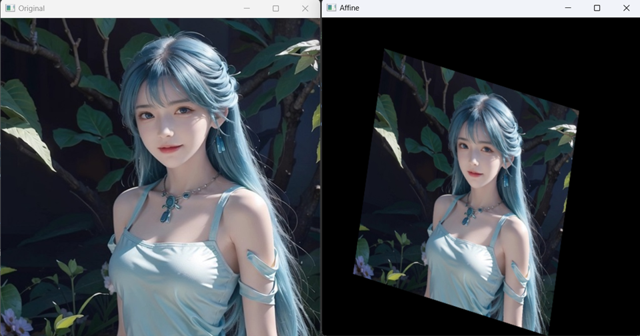
2.3 仿射变换
对于复杂仿射变换,OpenCV提供了函数cv2.getAffineTransform()来生成仿射函数cv2.warpAffine()所使用的转换矩阵M。
def affine():
image = cv.imread('./mini_img/test/girl-512.jpg')
rows, cols, _ = image.shape
src_pos = np.float32([[0, 0], [512, 0], [0, 512]])
dst_pos = np.float32([[100, 50], [412, 150], [50, 412]])
M = cv.getAffineTransform(src_pos, dst_pos)
new_img = cv.warpAffine(image, M, (cols, rows))
cv.imshow('Original', image)
cv.imshow('Affine', new_img)
cv.waitKey(0)
cv.destroyAllWindows()
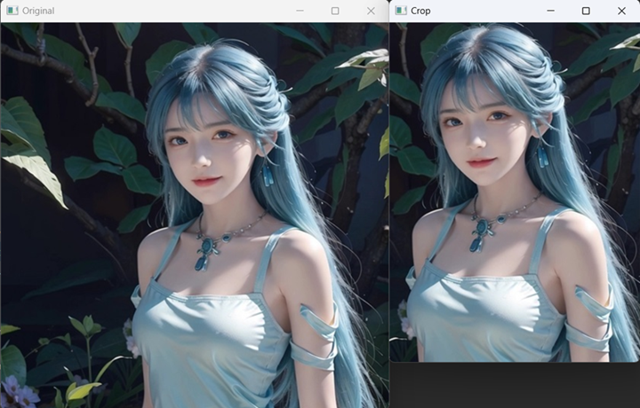
2.4 裁剪
本质是对图像像素矩阵切片
def crop():
image = cv.imread('./mini_img/test/girl-512.jpg')
crop_img = image[25:475, 150:480]
cv.imshow('Original', image)
cv.imshow('Crop', crop_img)
cv.waitKey(0)
cv.destroyAllWindows()
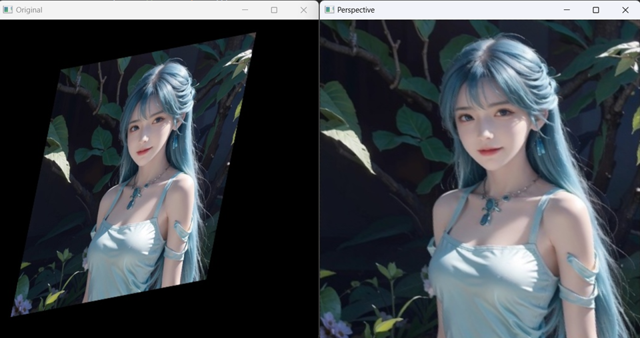
2.5 透视变换图像矫正
仿射变换是在二维空间中,而透视变换则是在三维空间中视角的变化。在OpenCV中,进行图像透视变换可以使用cv2.getPerspectiveTransform函数来获取变换矩阵,然后使用cv2.warpPerspective应用变换。
def perspective():
img = cv.imread('./mini_img/test/girl-affine.jpg')
rows, cols, _ = img.shape
src_pos = np.float32([[100, 80], [412, 20], [332, 415], [20, 475]])
dst_pos = np.float32([[0, 0], [cols, 0], [cols, rows], [0, rows]])
M = cv.getPerspectiveTransform(src_pos, dst_pos)
pers_img = cv.warpPerspective(img, M, (cols, rows))
cv.imshow('Original', img)
cv.imshow('Perspective', pers_img)
cv.waitKey(0)
cv.destroyAllWindows()
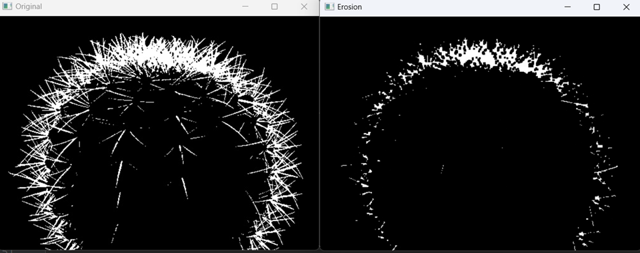
2.6 图像腐蚀
腐蚀操作通常用于去除图像中的噪声、分割连通区域、减小目标物体的尺寸等。腐蚀操作的原理是,在给定的结构元素下(kernel),遍历图像的每个像素,并将其值替换为该像素周围邻域内像素的最小值。结构元素控制了腐蚀的邻域范围和形状。邻域内的任何一个像素为黑色(0),则中心像素也将被置为黑色(0)。这样可以缩小或消除二值图像中的前景目标。
def erode():
image = cv.imread('./mini_img/test/cacti-bin.jpg', 0)
kernel = np.ones((3, 3), np.uint8)
erosion = cv.erode(image, kernel, iterations=1)
cv.imshow('Original', image)
cv.imshow('Erosion', erosion)
cv.waitKey(0)
cv.destroyAllWindows()
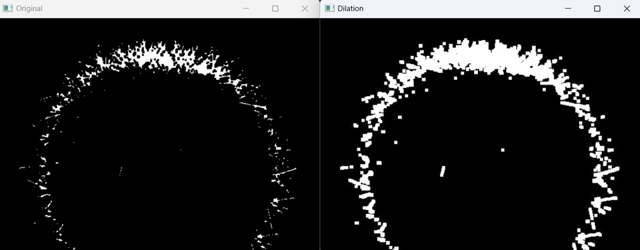
2.7 图像膨胀
在上面的腐蚀操作中,在消除噪声的同时,把有价值的信息也减少了。因此我们希望将这些有价值的信息增大,这样就要利用到膨胀操作。
def dilation():
image = cv.imread('./mini_img/test/cacti-erosion.jpg', 0)
kernel = np.ones((3, 3), np.uint8)
dilation = cv.dilate(image, kernel, iterations=2)
cv.imshow('Original', image)
cv.imshow('Dilation', dilation)
cv.waitKey(0)
cv.destroyAllWindows()
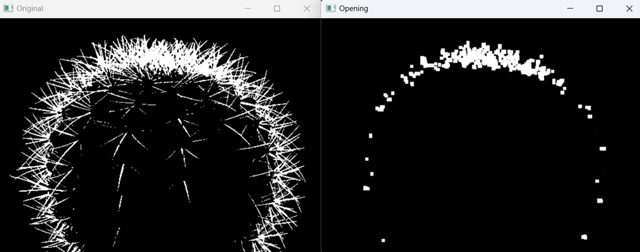
膨胀操作通常与腐蚀操作结合使用,以在图像中执行形态学处理。这种组合的方法称为开运算(Opening)和闭运算(Closing)
2.8 开运算
开运算是先进行腐蚀操作,再进行膨胀操作。它主要用于去除图像中的噪点、小的干扰物或者分离连通的对象。
def img_open():
image = cv.imread('./mini_img/test/cacti-bin.jpg', 0)
kernel = np.ones((3, 3), np.uint8)
# 开运算 - 先腐蚀后膨胀
opening = cv.morphologyEx(image, cv.MORPH_OPEN, kernel, iterations=2)
cv.imshow('Original', image)
cv.imshow('Opening', opening)
cv.waitKey(0)
cv.destroyAllWindows()
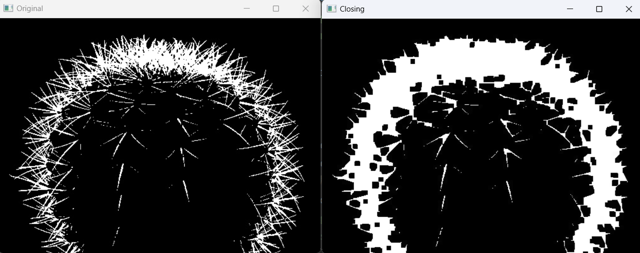
2.9 闭运算
闭运算是先进行膨胀操作,再进行腐蚀操作。它主要用于填充图像中的小洞孔或者连接分离的对象。
def img_close():
image = cv.imread('./mini_img/test/cacti-bin.jpg', 0)
kernel = np.ones((3, 3), np.uint8)
# 闭运算 - 先膨胀后腐蚀
closing = cv.morphologyEx(image, cv.MORPH_CLOSE, kernel, iterations=3)
cv.imshow('Original', image)
cv.imshow('Closing', closing)
cv.waitKey(0)
cv.destroyAllWindows()
2.10 礼帽与黑帽
礼帽 = 原始输入-开运算结果
黑帽 = 闭运算-原始输入
通过使用礼帽和黑帽操作,可以突出图像中细微的亮或暗结构,或者检测背景中的亮或暗区域。
def hat():
image = cv.imread('./mini_img/test/cacti-bin.jpg', 0)
kernel = np.ones((3, 3), np.uint8)
# 顶帽 - 原图像与闭运算结果的差
tophat = cv.morphologyEx(image, cv.MORPH_TOPHAT, kernel, iterations=3)
# 黑帽 - 开运算结果与原图像的差
blackhat = cv.morphologyEx(image, cv.MORPH_BLACKHAT, kernel, iterations=3)
cv.imshow('Original', image)
cv.imshow('Top Hat', tophat)
cv.imshow('Black Hat', blackhat)
cv.waitKey(0)
cv.destroyAllWindows()
2.11 梯度运算
梯度 = 膨胀-腐蚀
这里的梯度指的是图像梯度,可以简单地理解为像素的变化程度。几个连续的像素,其像素值跨度越大,则梯度值越大。梯度运算就是让原图的膨胀图像减去原图的腐蚀图像。因为膨胀图比原图大,腐蚀图像比原图小,利用腐蚀图像将膨胀图像掏空,就得到了原图的 轮廓图像(大概,并不精准)
def gradient():
image = cv.imread('./mini_img/test/solo-bin.jpg', 0)
kernel = np.ones((3, 3), np.uint8)
grad = cv.morphologyEx(image, cv.MORPH_GRADIENT, kernel, iterations=3)
cv.imshow('Original', image)
cv.imshow('Gradient', grad)
cv.waitKey(0)
cv.destroyAllWindows()

3 梯度
3.1 模糊
- 中值滤波
- 均值滤波
- 高斯滤波
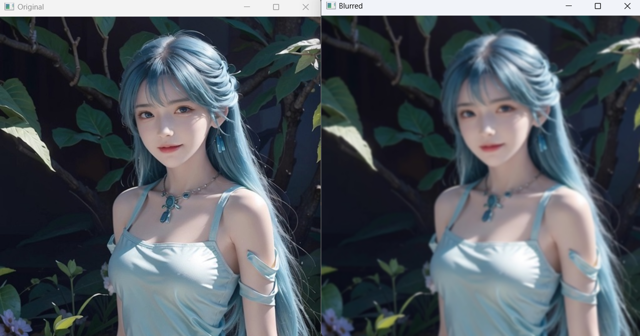
def blur_img():
image = cv.imread('./mini_img/test/girl-512.jpg')
ksize = (5, 5)
sigma_x = 0
blurred = cv.GaussianBlur(image, ksize, sigma_x)
cv.imshow('Original', image)
cv.imshow('Blurred', blurred)
cv.waitKey(0)
cv.destroyAllWindows()
3.2 锐化
图像锐化是一种突出和加强图像中景物的边缘和轮廓的技术,使图像变得更加清晰。它通过增强图像的高频分量来减少图像中的模糊,增强图像细节边缘和轮廓,增强灰度反差,便于后期对目标的识别和处理。
可自定义锐化算子,也可用常见的锐化方法:拉普拉斯锐化通常适用于需要快速锐化图像的场景,例如对模糊的图像进行简单的锐化处理。USM 锐化通常适用于需要对锐化效果进行精细控制的场景,例如对照片进行锐化处理。当然,也可以将两种方法结合使用,例如先使用拉普拉斯锐化进行快速锐化,然后再使用 USM 锐化进行精细调整。
def sharp():
img = cv.imread('./mini_img/test/girl-256.jpg')
kernel = np.float32([[0, -1, 0], [-1, 5, -1], [0, -1, 0]])
sharp1 = cv.filter2D(img, -1, kernel)
# USM锐化
gaussian = cv.GaussianBlur(img, ksize=(7, 7), sigmaX=3)
sharp2 = cv.addWeighted(img, 2, gaussian, -1, 0)
titles = ["Origin", "Sharpen", "USM"]
images = [img, sharp1, sharp2]
for i, (title, image) in enumerate(zip(titles, images), 1):
plt.subplot(1, 3, i)
plt.imshow(cv.cvtColor(image, cv.COLOR_BGR2RGB))
plt.title(title)
plt.xticks([])
plt.yticks([])
plt.suptitle('Sharp Image Example', fontsize=16, x=0.5, y=0.25)
plt.show()

3.3 边缘检测
边缘检测识别图像中明亮度变化显著的点。这些点通常对应于图像中物体的轮廓,如物体的边缘、面的边界以及其他的图像特征。边缘检测的目的通常是为了简化图像数据,提取出对后续处理更有用的结构信息,或者为图像分析和识别提供重要的预处理步骤。
边缘检测算法通过识别亮度(灰度或颜色)的一阶导数或二阶导数的突变来检测边缘。图像的一阶导数可以突出图像的边缘信息,而二阶导数则能突出边缘的变化,也就是边缘的边缘。常用边缘检测算子:
- Sobel
- Scharr
- Laplacian
- Canny
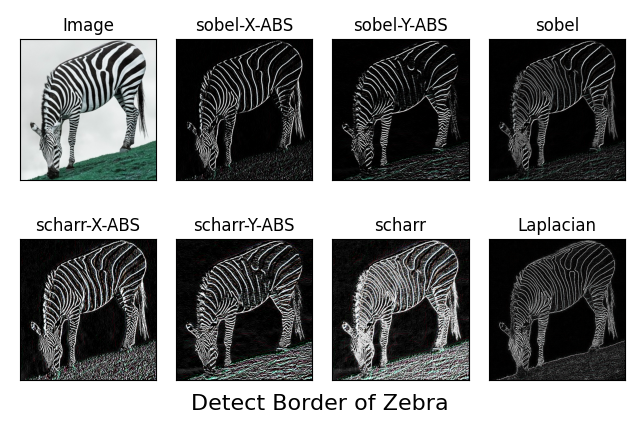
def detect_border():
img = cv.imread('./mini_img/test/zebra-grass.jpg')
sobel_x = cv.Sobel(img, -1, dx=1, dy=0, ksize=3)
sobel_y = cv.Sobel(img, -1, dx=0, dy=1, ksize=3)
sobel_xabs = cv.convertScaleAbs(sobel_x)
sobel_yabs = cv.convertScaleAbs(sobel_y)
sobel = cv.addWeighted(sobel_xabs, 0.5, sobel_yabs, 0.5, 0)
scharr_x = cv.Scharr(img, -1, dx=1, dy=0)
scharr_y = cv.Scharr(img, -1, dx=0, dy=1)
scharr_xabs = cv.convertScaleAbs(scharr_x)
scharr_yabs = cv.convertScaleAbs(scharr_y)
scharr = cv.addWeighted(scharr_xabs, 0.9, scharr_yabs, 0.9, 0)
Laplacian = cv.Laplacian(img, -1, ksize=3)
titles = ["Image", "sobel-X-ABS", "sobel-Y-ABS", "sobel",
"scharr-X-ABS", "scharr-Y-ABS", "scharr", "Laplacian"]
images = [img, sobel_xabs, sobel_yabs, sobel,
scharr_xabs, scharr_yabs, scharr, Laplacian]
for i in range(len(titles)):
plt.subplot(2, 4, i + 1)
plt.imshow(images[i], cmap="gray")
plt.title(titles[i])
plt.xticks([])
plt.yticks([])
plt.suptitle('Detect Border of Zebra', fontsize=16, x=0.5, y=0.08)
plt.show()
Canny边缘检测算法通过多个阶段的处理,能够得到清晰准确的边缘信息,并且对噪声具有一定的鲁棒性。因此,它在图像处理和计算机视觉中得到广泛应用,特别是在要求高精度边缘检测的场景中。
Canny边缘检测的主要步骤如下:
- 噪声抑制:首先,通过使用高斯滤波器对图像进行平滑处理,以去除图像中的噪声。高斯滤波器可以有效地平滑图像,同时保持边缘的细节。
- 计算梯度幅值和方向:使用Sobel算子计算图像中每个像素点的水平和垂直方向的梯度值。然后,根据梯度值计算每个像素点的梯度幅值和方向。
- 非极大值抑制:在计算得到的梯度幅值图像上进行非极大值抑制。这一步的目的是将边缘宽度变窄,使得边缘更加细化和明确。
- 双阈值处理:根据设定的高阈值和低阈值,将梯度幅值图像中的像素点分为强边缘、弱边缘和非边缘三类。通常选择高阈值和低阈值使得强边缘像素点的梯度幅值大于高阈值,非边缘像素点的梯度幅值小于低阈值,而弱边缘像素点的梯度幅值处于高阈值和低阈值之间。
- 边缘连接:最后,通过连接强边缘像素点和与之相邻的弱边缘像素点,得到完整的边缘图像。
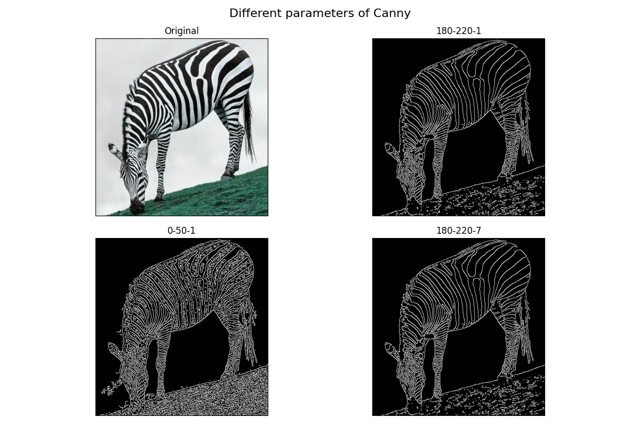
def canny():
img = cv.imread('./mini_img/test/zebra-grass.jpg')
img = cv.resize(img, None, fx=0.8, fy=0.8, interpolation=cv.INTER_CUBIC)
params = [(180, 220, 1), (0, 50, 1), (180, 220, 7)]
titles = ['Original']
images = [img]
for min_threshold, max_threshold, aperture in params:
border = cv.Canny(img, min_threshold, max_threshold, aperture)
images.append(border)
titles.append(f'{min_threshold}-{max_threshold}-{aperture}')
plt.figure(figsize=(12, 8))
for i, (title, image) in enumerate(zip(titles, images), 1):
plt.subplot(2, 2, i)
plt.imshow(image, cmap="gray")
plt.title(title)
plt.xticks([])
plt.yticks([])
plt.suptitle('Different parameters of Canny', fontsize=16, x=0.5, y=0.98)
plt.show()
4 轮廓
寻找目标图像的轮廓并绘制出该轮廓是我们进行图像识别时常用的手段,轮廓是图像中连续的边界线,可以用于物体检测、形状分析等应用。为了获取更高的准确性,会先进行二值化处理,在得到二进制图像后,寻找轮廓就是从黑色背景中找到白色物体,因此我们要找的对象应是白色,背景应该是黑色。
def contour():
image = cv.imread('./mini_img/test/zebra-grass.jpg')
gray = cv.cvtColor(image, cv.COLOR_BGR2GRAY)
_, thresh = cv.threshold(gray, 160, 255, cv.THRESH_BINARY)
contours, hierarchy = cv.findContours(thresh, cv.RETR_TREE, cv.CHAIN_APPROX_SIMPLE)
contours_filtered = tuple(c for c in contours if c.shape[0] > 50)
new_img = copy.deepcopy(image)
cv.drawContours(new_img, contours_filtered, -1, (0, 0, 255), 2)
for i, (title, img) in enumerate(zip(['Original', 'Contours'], [image, new_img]), 1):
plt.subplot(1, 2, i)
plt.imshow(cv.cvtColor(img, cv.COLOR_BGR2RGB))
plt.title(title)
plt.xticks([])
plt.yticks([])
plt.suptitle('Draw Contours of Zebra', fontsize=16, x=0.5, y=0.20)
plt.show()

5 视频处理
视频是由大量的图像构成的,这些图像是以固定的时间间隔从视频中获取的。这样,就能够使用图像处理的方法对这些图像进行处理,进而达到处理视频的目的。要想处理视频,需要先对视频进行读取、显示、保存等相关操作。为此,OpenCV提供了VideoCapture类和 VideoWiter 类的相关方法。
5.1 读取摄像头视频
def camera_video():
capture = cv.VideoCapture(0)
while capture.isOpened():
ret, image = capture.read()
if not ret:
continue
cv.imshow("Video", image)
key = cv.waitKey(1)
if key == 32: # 空格键
break
capture.release()
cv.destroyAllWindows()
5.2 处理摄像头视频
def trans_camera_video():
capture = cv.VideoCapture(0, cv.CAP_DSHOW)
while capture.isOpened():
ret, image = capture.read()
if not ret:
continue
image_trans = cv.cvtColor(image, cv.COLOR_BGR2HLS)
rm_img = copy.deepcopy(image)
rm_img[:, :, 1] = 0
cv.imshow("Video", image)
cv.imshow("Trans_Color_Space", image_trans)
cv.imshow("Remove_Green_Channel", rm_img)
key = cv.waitKey(1)
if key == 32:
break
capture.release()
cv.destroyAllWindows()
5.3 读取播放本地视频
def play_video(video_path):
video = cv.VideoCapture(video_path)
fps = video.get(cv.CAP_PROP_FPS)
frame_count = video.get(cv.CAP_PROP_FRAME_COUNT)
frame_width = int(video.get(cv.CAP_PROP_FRAME_WIDTH))
frame_height = int(video.get(cv.CAP_PROP_FRAME_HEIGHT))
print("帧速率:", fps)
print("帧数:", frame_count)
print("帧宽度:", frame_width)
print("帧高度:", frame_height)
while video.isOpened():
ret, image = video.read()
if not ret:
break
cv.namedWindow("Video", 0)
cv.resizeWindow("Video", frame_width // 3, frame_height // 3)
cv.imshow("Video", cv.flip(image, -1))
key = cv.waitKey(1)
if key == 32:
cv.waitKey(0)
continue
if key == 27: # Esc键
break
video.release()
cv.destroyAllWindows()
5.4 处理和保存本地视频
def save_video(video_path):
video = cv.VideoCapture(video_path)
fps = video.get(cv.CAP_PROP_FPS)
size = (int(video.get(cv.CAP_PROP_FRAME_WIDTH)),
int(video.get(cv.CAP_PROP_FRAME_HEIGHT)))
fourcc = cv.VideoWriter_fourcc('X', 'V', 'I', 'D') # 编码格式
root_path, _ = os.path.split(video_path)
output = cv.VideoWriter(os.path.join(root_path, 'hls.avi'), fourcc, fps, size)
while video.isOpened():
ret, frame = video.read()
if not ret:
break
image = cv.cvtColor(frame, cv.COLOR_BGR2HLS)
output.write(cv.flip(image, -1))
print("视频转换保存完成")
video.release()
output.release()